GPUs¶
GPU Quick Start¶
Using your favorite text editor, create a new file gpu.sh with the following contents…
#!/bin/bash
#SBATCH --partition=gpu2
#SBATCH --time=00:15:00
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --gres=gpu:tesla:1
#SBATCH --job-name="gpu_matrixmulti"
#SBATCH --output=gpu_matrixmulti.out
#SBATCH --mail-type=ALL
module load cuda11.0/toolkit
/tools/gpu/cuda-toolkit/11.0/samples/0_Simple/matrixMul/matrixMul -wA=6400 -hA=3200 -wB=3200 -hB=6400
The script will set the partition to gpu2 which contains nodes with GPU devices, and request one GPU device with the --gres=gpu:tesla:1 parameter.
The last two lines will modify your environment to reflect the necessary GPU libraries, etc. and then execute a simple matrix multiplication program that will run on the GPU.
To submit the job, run the following sbatch command.
sbatch gpu.sh
Your output should be located in the file gpu_matrixmulti.out in your working directory.
Easley GPU Devices¶
Easley GPU nodes are equipped with NVIDA Tesla T4 devices, with the following specs …
40 Multiprocessors, 64 CUDA Cores/MP: |
2560 CUDA Cores |
GPU Max Clock rate: |
1590 MHz (1.59 GHz) |
Memory Clock rate: |
5001 Mhz |
Memory Bus Width: |
256-bit |
L2 Cache Size: |
4194304 bytes |
Maximum Texture Dimension Size (x,y,z) |
1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384) |
Maximum Layered 1D Texture Size, (num) layers |
1D=(32768), 2048 layers |
Maximum Layered 2D Texture Size, (num) layers |
2D=(32768, 32768), 2048 layers |
Total amount of constant memory: |
65536 bytes |
Total amount of shared memory per block: |
49152 bytes |
Total number of registers available per block |
65536 |
Warp size: |
32 |
Maximum number of threads per multiprocessor: |
1024 |
Maximum number of threads per block: |
1024 |
Max dimension size of a thread block (x,y,z): |
(1024, 1024, 64) |
Max dimension size of a grid size (x,y,z): |
(2147483647, 65535, 65535) |
Maximum memory pitch: |
2147483647 bytes |
Texture alignment: |
512 bytes |
Concurrent copy and kernel execution: |
Yes with 3 copy engine(s) |
Run time limit on kernels: |
No |
Integrated GPU sharing Host Memory: |
No |
Support host page-locked memory mapping: |
Yes |
Alignment requirement for Surfaces: |
Yes |
Device has ECC support: |
Enabled |
Device supports Unified Addressing (UVA): |
Yes |
Device supports Managed Memory: |
Yes |
Device supports Compute Preemption: |
Yes |
Supports Cooperative Kernel Launch: |
Yes |
Supports MultiDevice Co-op Kernel Launch: |
Yes |
Device PCI Domain ID / Bus ID / location ID: |
0 / 59 / 0 |
Scheduling GPUs¶
Two GPU partitions exist, based on the number of GPU devices that are present per node.
Partition |
Num GPUs |
Sample Job Submission |
|---|---|---|
gpu2 |
2 |
sbatch -p gpu2 –gres=gpu:tesla:2 |
gpu4 |
4 |
sbatch -p gpu4 –gres=gpu:tesla:4 |
Interactive GPU Jobs¶
For testing GPU allocations, viewing hardware capabilities, or debugging GPU code/jobs, you can establish an interactive shell on a GPU node with salloc
The generalized syntax is
salloc <-N<number of nodes>> [-n<number of tasks/processes>] -p <gpu2|gpu4|<lab_name>_gpu2|<lab_name>_gpu4> --gres=gpu:tesla:<number of gpu devices>
For example, to request a single GPU device in the community gpu2 partition (nodes with 2x GPU devices) …
salloc -N1 -p gpu2 --gres=gpu:tesla:1
As a basic test, to see the GPU device details and current stats …
module load cuda11.0/toolkit
nvidia-smi
Wed Dec 9 23:57:35 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.80.02 Driver Version: 450.80.02 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:3B:00.0 Off | 0 |
| N/A 42C P8 9W / 70W | 0MiB / 15109MiB | 0% E. Process |
| | | N/A |
+-------------------------------+----------------------+----------------------+
GPU Overview¶
GPU Terminology¶
CUDA: Compute Unified Device Architecture is the programming model (and corresponding language constructs) designed to support the use of GPUs for general purpose computing. CUDA can be conceptualized as an interface for sending programmatic instructions to the GPU, while also serving as the bridge between the GPU and the more general system, e.g. the CPU.
Kernel: Not to be confused with operating system kernels, in GPU terminology, a kernel is roughly equivalent to the device-bound program (or set of instructions) to be executed. More specifically, a CUDA kernel is the parallel portion of an application instantiated on the GPU device, which is typically implemented as a specially coded function within the program code.
Streaming Multiprocessor (SM): GPU devices have multiple SMs which can be viewed as a small CPU. Like a CPU, each SM has its own internal cores, registers, caches, etc.
CUDA Core: In NVIDIA architectures, each SM contains multiple CUDA cores, which execute instructions passed to it by individual threads.
Warp: A warp is a collection of (typically 32) threads (see GPU Architecture). Each thread in a warp executes the same instructions, on different chunks of data.
GPU Architecture¶
Graphics Processing Units (GPUs) were traditionally designed to offload computational overhead for software that required high-end visual graphics capabilities, like 3D games and video editing programs. Over time, programmers discovered that the architecture employed by GPUs, which performed rapid computation for three-dimensional vectors (e.g. red, green, and blue) could also be applied to different, more scientific, workloads. Not to miss out on such lucrative opportunities, GPU hardware vendors have made advancments in both software and hardware constructs to support such applications. To help understand how GPUs can provide such capabilities, a basic understanding of the underlying architecture is necessitated.
Perhaps the best way to conceptialize the GPU computational model is to compare it to a general purpose CPU, which serve as the foundation for most of the more familiar computer architectures. The primary goal of a CPU is to perform a variety of arbitrary tasks with very low latency, so that multiple programs with a wide range of instructions can exist in relative harmony. With GPUs, the goal is slightly more specific, in that the instructions executed are more limited, but can be executed with much more parallelism with a higher tolerance for latency. The most important realization is that GPUs are able to employ a much larger number of special purpose cores than are typically found on a general purpose CPU.
To illustrate this, let’s look at the architectural diagram of a very basic GPU architecture compared to that of a more general purpose CPU …
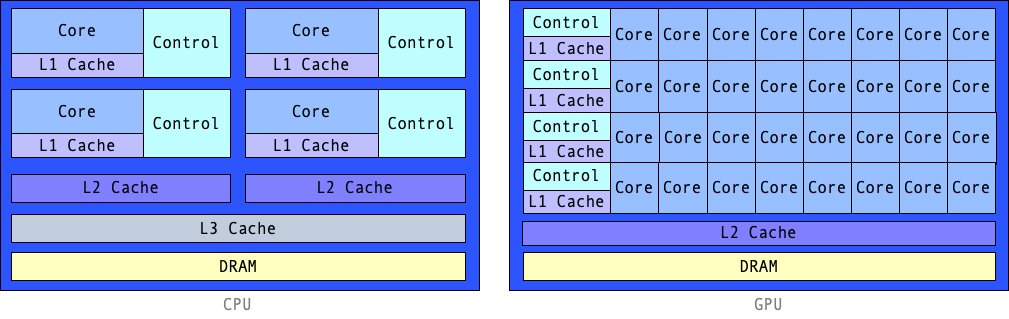
CPU vs. GPU Chip Architecture¶
As seen in this illustration, the GPU employs a much larger number of cores, with less emphasis on the instruction set (control) and internal memory per core (cache). Thus, much higher potential parallelism for workloads that employ a constrained set of instructions, and more tolerance for latency due to decreased memory capacity. Of course, this basic comparison is much more complex in reality, as illustrated by the more recent NVIDIA Turing Architecture depicted below…
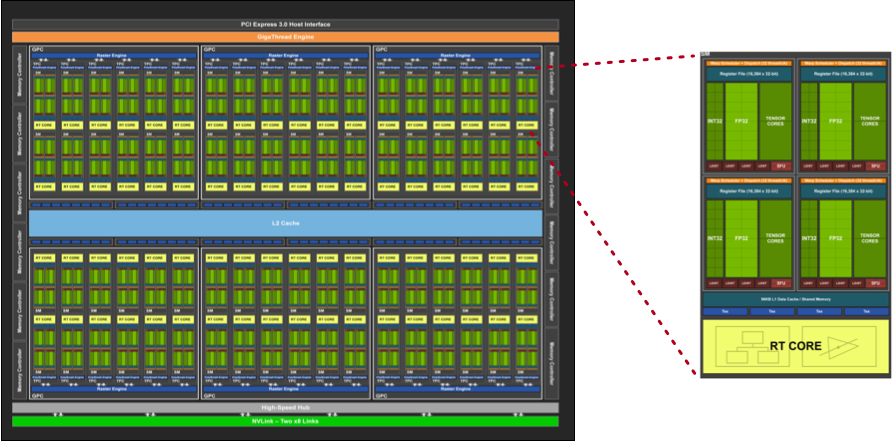
NVIDIA Turing Architecture¶
Right, so there is much more complexity here than we really need to understand in order to use GPUs, but visualizing the GPU architecture helps to further our insight into the programmatic elements. First, we see that the GPU device itself looks somewhat like a two-dimensional plane of components. This can be visualized as a grid of x and y coordinates, roughly corresponding to a collection of hardware elements. These processing elements are termed stream multiprocessors (SMs), and within each of those exists multiple CUDA cores, which can be futher indexed to additional x and y coordinates within the SM. This model will assist with the programming nuances that are used for interfacing with the GPU via CUDA.
Thread Hierarchy¶
With a cursory glance at the GPU architecture, we can see that the GPU device itself can be represented as a grid, or matrix, of SMs, and within each SM we have a number of GPU (CUDA in NVIDIA terminology) cores. This is best represented in a thread hierarchy where the instructions bound for the GPU are first categorized into the overarching device plane, then into the middle SM construct, and finally into the basic unit of execution…
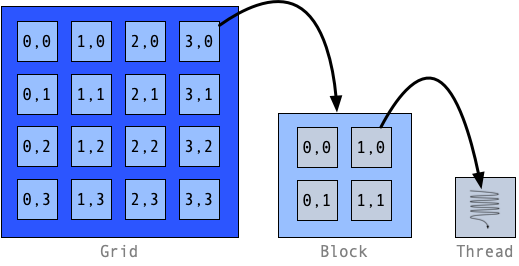
GPU Thread Hierarchy¶
Grid: A grid organizes multiple blocks of threads into a matrix. Each block can be referenced by its x and y coordinates. A grid maps conceptually onto the GPU device itself, i.e. a set of multiple streaming multiprocessors (SMs).
Block: A mechanism for organizing multiple threads into an addressable (indexed) one, two or three-dimensional matrix. A thread block is executed by the GPU streaming multiprocessor (SM).
Thread: The basic unit of execution. A thread is executed by a CUDA core.
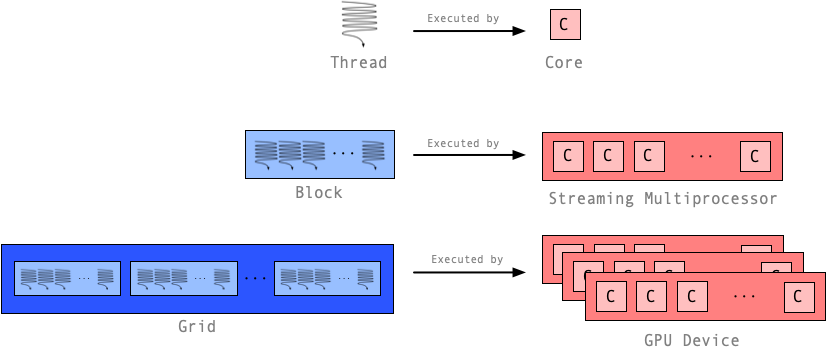
GPU Thread Hierarchy Mapped to Execution Context¶